Introduction
Ça y est, c’est le grand jour, tu as regardé des tutoriels sur Kubernetes pour remplacer ta VM avec tes 50 containeurs Docker et tu te lances dans l’installation de ta première application !
Au début tout va bien, tu profites de ton cluster ou éventuellement de Minikube sur ton poste, tu crées un Deployment, puis un Service, et tout fonctionne comme prévu dans le meilleur des mondes.
Déployer c’est bien, mais pouvoir accéder à ses ressources c’est encore mieux, alors tu continue de suivre le tutoriel et tu fais un port-forward pour accéder à ton application, sans problèmes particulier, life is good.
Mais quelques questions devraient normalement commencer à remonter…
- Faire du port forward c’est bien pour du test, mais comment gérer ça en production ?
- On me parle de Service, de NodePort et de LoadBalancer, mais que choisir ?
Et surtout, comment choisir une solution adapté à mon utilisation ?
Avec un peu de chances, les cloud providers ont eu raison de toi, et tu as créé ton premier cluster sur Scaleway, OVH, AWS, … Si c’est le cas, alors le choix est plutôt simple, il suffit de créer un LoadBalancer, et ton cloud provider se chargera de créer la ressources correspondante et une adresse IP te sera attribué sur Kubernetes.
Mais si tu as déployé ton cluster OnPremise, tu devrais te retrouver avec une ressource LoadBalancer qui reste en Pending :
kubectl get svc -n my-app
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEloadbalancer LoadBalancer 10.43.252.251 <pending> 80:31416/TCP 2sEt c’est là où les choses intéressantes commencent, comment gérer ça relativement proprement ?
MetalLB
Une des solutions populaire, notamment OnPrem est d’utiliser MetalLB.
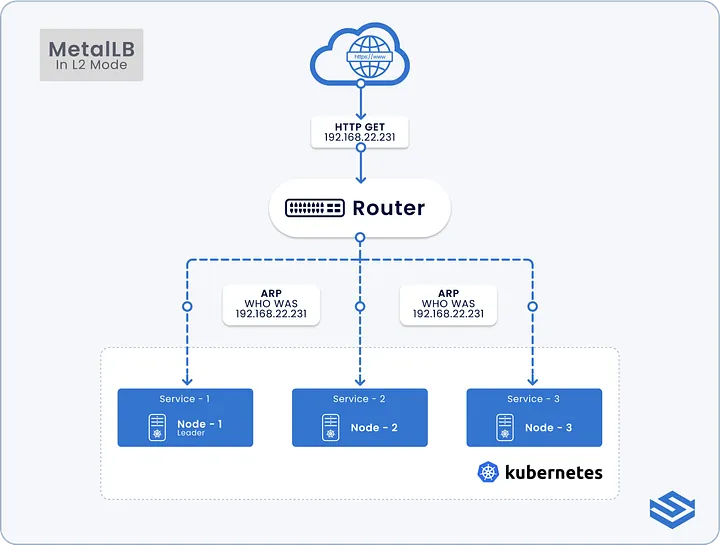
MetalLB est un load-balancer layer 2 (ARP) et layer 3 (BGP) pour Kubernetes. Il permet de fournir une adresse IP externe à tes services Kubernetes en utilisant un pool d’adresses IP que tu as à ta disposition.
Niveau 2
Quelques explications
Si on lit ce qui est écrit sur la documentation MetalLB pour du niveau 2, on peut voir quelques avantages et inconvénients à l’utilisation de cette solution.
Son principal avantage est qu’il est simple à utiliser et s’adapte à beaucoup de cas d’usage. Lorsqu’une adresse IP est allouée, alors un des noeuds du cluster va répondre à cette adresse IP en répondant aux requêtes ARP qui sont envoyées par les clients.
Mais c’est là aussi un des points négatifs de la solution, un seul des noeuds du cluster sera en capacité de gérer le trafic pour une adresse IP donnée, ce qui entraîne 2 points négatifs :
- Bascule (failover) potentiellement lente en cas de perte de noeud : Si le noeud qui gère l’adresse IP devient indisponible, alors il faut attendre que le client envoie une requête ARP pour que le nouveau noeud prenne le relais, ou que le client soit en capacité d’interpréter les paquets que MetalLB envoie pour les informer d’un changement d’adresse MAC
- Goulot d’étranglement pour le noeud qui gère le trafic d’une adresse IP : Comme expliqué juste au dessus, dans ce mode de fonctionnement, seul un noeud élu reçoit le trafic pour une adresse IP donnée. Si le noeud arrive à sa capacité réseau limite, alors il n’y aura pas de possibilité de montée en charge supplémentaire
Trop de théorie, pas assez de pratique
Si on suit la documentation d’installation de MetalLB, on peut se satisfaire de kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.15.2/config/manifests/metallb-native.yaml pour l’installer.
Je suis plutôt partisan d’utiliser une chart helm pour gérer ça en GitOps via ArgoCD/FluxCD, mais là on n’est pas en production 😎
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.15.2/config/manifests/metallb-native.yaml
namespace/metallb-system createdcustomresourcedefinition.apiextensions.k8s.io/bfdprofiles.metallb.io createdcustomresourcedefinition.apiextensions.k8s.io/bgpadvertisements.metallb.io createdcustomresourcedefinition.apiextensions.k8s.io/bgppeers.metallb.io createdcustomresourcedefinition.apiextensions.k8s.io/communities.metallb.io createdcustomresourcedefinition.apiextensions.k8s.io/ipaddresspools.metallb.io createdcustomresourcedefinition.apiextensions.k8s.io/l2advertisements.metallb.io createdcustomresourcedefinition.apiextensions.k8s.io/servicebgpstatuses.metallb.io createdcustomresourcedefinition.apiextensions.k8s.io/servicel2statuses.metallb.io createdserviceaccount/controller createdserviceaccount/speaker createdrole.rbac.authorization.k8s.io/controller createdrole.rbac.authorization.k8s.io/pod-lister createdclusterrole.rbac.authorization.k8s.io/metallb-system:controller createdclusterrole.rbac.authorization.k8s.io/metallb-system:speaker createdrolebinding.rbac.authorization.k8s.io/controller createdrolebinding.rbac.authorization.k8s.io/pod-lister createdclusterrolebinding.rbac.authorization.k8s.io/metallb-system:controller createdclusterrolebinding.rbac.authorization.k8s.io/metallb-system:speaker createdconfigmap/metallb-excludel2 createdsecret/metallb-webhook-cert createdservice/metallb-webhook-service createddeployment.apps/controller createddaemonset.apps/speaker createdvalidatingwebhookconfiguration.admissionregistration.k8s.io/metallb-webhook-configuration createdEt là c’est parti, on peut commencer à s’amuser !
On commencer par définir une IPAddressPool :
apiVersion: metallb.io/v1beta1kind: IPAddressPoolmetadata: name: main-pool namespace: metallb-systemspec: addresses: - 172.16.112.10-172.16.112.20Puis un L2Advertisement afin que notre pool soit fonctionnelle :
apiVersion: metallb.io/v1beta1kind: L2Advertisementmetadata: name: main-l2 namespace: metallb-systemspec: ipAddressPools: - main-poolSi on reprend l’application et qu’on modifie le service default/frontend pour spécifier le type: LoadBalancer, on devrait avoir une IP dans le pool qui nous est assignée.
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEfrontend LoadBalancer 10.43.212.166 172.16.112.12 80:31393/TCP 65mUn curl sur l’adresse ip nous confirme que tout fonctionne comme prévu :
curl 172.16.112.12
<html ng-app="redis"> <head> <title>Guestbook</title> <link rel="stylesheet" href="//netdna.bootstrapcdn.com/bootstrap/3.1.1/css/bootstrap.min.css">....On peut même aller un peu plus loin pour savoir quel noeud gère l’adresse IP de notre Balancer :
kubectl get servicel2statuses -n metallb-system
NAME ALLOCATED NODE SERVICE NAME SERVICE NAMESPACEl2-4zfrt test-node-02 frontend defaultEt voilà, notre service est accessible depuis l’extérieur du cluster en utilisant MetalLB
Niveau 3
Pour répondre à des besoins plus complexes, MetalLB propose un mode de fonctionnement dit “niveau 3” qui permet de distribuer le trafic sur plusieurs noeuds. Pour cela, MetalLB utilise le protocole BGP (Border Gateway Protocol).
Je passe volontairement cette partie étant donné que Cilium possède un fonctionnement similaire, et je préfère tout autant gérer ça avec le composant du cluster qui gère le réseau !
Cilium
Mais qu’est-ce que Cilium ?
Cilium c’est une CNI (Container Network Interface) basé sur eBPF qui permet de gérer la couche réseau d’un Cluster Kubernetes.
Cilium permet entre autres de :
- Gérer le réseau dans le cluster entre les pods, services, …
- D’obtenir d’avantage de visiblité sur ce qui se passe dans le cluster, principalement grâce à Hubble, mais pas que
- Gérer une Gateway API sans déployer de composants supplémentaire
- Utiliser du mTLS, c’est certes en Beta mais c’est super intéressant 😅
- Faire du Cluster Mesh afin de faire du Multi-Cluster
- …
Bref la techno est clairement intéressante, et je n’arriverais pas à tout mettre en valeur proprement, je vous conseille d’aller vous renseigner d’avantage si ça vous intéresse.
Les joies du BGP
Une des fonctionnalités de Cilium est de pouvoir gérer le BGP (Border Gateway Protocol) pour exposer les services du cluster sur le réseau local.
L’idée est de pouvoir annoncer les adresses IP d’un cluster Kubernetes via du BGP afin que les adresses soient routables/accessibles.
Mon idée dans tout cas, c’est de pouvoir s’en servir avec la fonctionnalité d’IPAM, et ainsi définir une plage d’adresse IP pour nos services de type LoadBalancer !
Passe à la pratique
Dans mon cas d’usage, j’utilise un Unifi UDM SE en tant que routeur qui possède la fonctionnalité BGP, comme beaucoup d’autres routeurs/pare-feux du marché. Les configurations seront forcément à adapter en fonction de votre environnement.
Configuration côté Cilium
Côté Cilium, il faut s’assurer que la configuration possède bien la clé bgpControlPlane.enabled côté chart helm soit à true, comme le spécifie la documentation
Si Helm n’est pas votre ami (pourquoi ?!), vous pouvez vérifier que la clé enable-bgp-control-plane dans la configmap kube-system/cilium-config soit bien set à true
Et c’est parti ! Il faut choisir 2 numéros d’AS (Autonomous System) différents, un pour le routeur et un pour Cilium (qui représente le cluster Kubernetes). Si on vérifie la plage de wiki, on peut voir que la plage 64512-65534 est réservée pour un usage, on peut donc s’en servir pour notre cas d’usage
De mon côté je vais prendre l’AS 65000 pour mon routeur, et l’AS 65001 pour Cilium.
Côté configuration Cilium, plusieurs méthodes sont disponibles, malheureusement je ne suis pas un expert réseau, donc je vais prendre la méthode qui m’arrange en utilisant la Default Gateway Auto-Discovery
apiVersion: cilium.io/v2kind: CiliumBGPClusterConfigmetadata: name: cilium-bgpspec: bgpInstances: - name: "65000" localASN: 65001 localPort: 179 peers: - name: "peer-65001-udm" peerASN: 65000 autoDiscovery: mode: "DefaultGateway" defaultGateway: addressFamily: ipv4 peerConfigRef: name: "cilium-peer"Puis on définit CiliumBGPPeerConfig :
apiVersion: cilium.io/v2kind: CiliumBGPPeerConfigmetadata: name: cilium-peerspec: gracefulRestart: enabled: true restartTimeSeconds: 15 families: - afi: ipv4 safi: unicast advertisements: matchLabels: advertise: "bgp"Ensuite on configure le CiliumBGPAdvertisement pour qu’il n’annonce que les routes vers les service de type LoadBalancer, il y a la possibilité d’annoncer aussi les services ClusterIP, les PodCIDR, … Mais ce n’est pas forcément ce que l’on recherche ici étant donné que l’on veut uniquement accéder à nos services depuis l’extérieur du cluster.
Le selector est important, autrement aucun service ne sera annoncé par cilium
apiVersion: cilium.io/v2kind: CiliumBGPAdvertisementmetadata: name: bgp-advertisements labels: advertise: bgpspec: advertisements: - advertisementType: "Service" service: addresses: - LoadBalancerIP selector: # <-- used to trigger all LB services matchExpressions: - {key: randomKey, operator: NotIn, values: ['never-used-value']}Enfin, comme pour MetalLB, on définit une pool d’adresse IP que Cilium pourra utiliser pour nos services LoadBalancer :
apiVersion: "cilium.io/v2alpha1"kind: CiliumLoadBalancerIPPoolmetadata: name: main-lb-ip-poolspec: blocks: - start: "172.16.112.10" stop: "172.16.112.20"Configuration côté Unifi UDM SE
Côté UDM SE, on doit faire une configuration FRR BGP pour la pousser sur l’interface Web.
La configuration en question en faisant attention de bien lister tous les neighbors (oui je sais, j’aurais du changer l’adresse IP de mes noeuds 😅) :
router bgp 65000 bgp router-id 172.16.112.1 neighbor main-cluster peer-group neighbor main-cluster remote-as 65001 neighbor main-cluster activate neighbor main-cluster soft-reconfiguration inbound neighbor main-cluster default-originate neighbor 172.16.112.156 peer-group main-cluster neighbor 172.16.112.160 peer-group main-cluster neighbor 172.16.112.114 peer-group main-cluster address-family ipv4 unicast redistribute connected neighbor main-cluster activate neighbor main-cluster route-map ALLOW-ALL in neighbor main-cluster route-map ALLOW-ALL out neighbor main-cluster next-hop-selfexit-address-familyroute-map ALLOW-ALL permit 10!line vty!Et maintenant, comment on vérifie si ça fonctionne ?
Dans un mon cas, un simple curl -L http://172.16.112.12 permet de valider que les routes sont bien annoncés correctement !
Si on veut pousser le bouchon un peu plus loin, on peut aller voir les routes directement sur le routeur :
~# ip route
<...>172.16.112.12 proto bgp metric 20 nexthop via 172.16.112.114 dev br112 weight 1 nexthop via 172.16.112.156 dev br112 weight 1 nexthop via 172.16.112.160 dev br112 weight 1<...>Et si on faisait ça différemment ?
Si je vous disais que vous pouvez accéder aux services qui se trouvent dans votre cluster sans avoir besoin de LoadBalancer, ni de Nodeport, est-ce que vous me croiriez ? Non ? Et pourtant…
Tailscale
Mais qu’est-ce Tailscale ?
Tailscale c’est un outil vous servant à créer un réseau privé virtuel (VPN) mesh, basé sur Wireguard et qui est beaucoup plus simple d’utilisation qu’un VPN “traditionnel”.
En quelques points clés :
-
Tailscale permet de créer un réseau privé entre vos appareils — ordinateurs, téléphones, serveurs — même s’ils sont chacun sur des réseaux différents (Wi-Fi public, maison, travail, etc.) via un réseau appelé “tailet”
-
Tailscale s’appuie sur le protocole WireGuard
-
Tailscale propose une configuration “zero-config” : peu ou pas de réglage de réseau, peu de ports à ouvrir, etc. L’idée c’est que ça marche sans avoir à se prendre la tête avec des règles de pare-feu, des configurations de routeur, etc.
Si certains connaissent Zerotier ou encore Netmaker, le principe est le même, mais la configuration est encore plus simple 😎
Et pourquoi c’est intéressant ?
Et bien, principalement parce que Tailscale peut être installé dans un cluster Kubernetes !
Plusieurs options de déploiements sont disponibles :
- Déploiement via un sidecar afin de permettre de n’accéder qu’à un pod dans le cluster sans exposer le reste des pods/services
- Déploiement d’un proxy, similaire au déploiement d’un sidecar mais plutôt utilisé pour pointer vers un service plutôt qu’un pod
- Déploiement d’un routeur, permettant d’accéder à tout ce qui se trouve dans le cluster
Les déploiements via un sidecar, ou un proxy sont probablement les solutions les plus adaptées à de la production, mais ce n’est clairement pas les plus funs à utiliser. On est donc parti pour le déploiement d’un routeur afin d’accéder à tout ce qui se trouve sur notre cluster.
C’est parti pour le déploiement
Pour nous cas d’utilisation, on déploie ça en s’inspirant de la définition du Pod présent sur la documentation de tailscale
WARNINGJe vais passer des secrets en clair afin simplifier le test pour cet article, mais pensez bien à passer vos variables dans un Secret pour gérer ça proprement !
On commence par définir les RBACs nécessaires pour que Tailscale puisse fonctionner correctement, avec les manifests présents sur la doc Tailscale:
---# Copyright (c) Tailscale Inc & AUTHORS# SPDX-License-Identifier: BSD-3-ClauseapiVersion: rbac.authorization.k8s.io/v1kind: Rolemetadata: name: tailscalerules:- apiGroups: [""] # "" indicates the core API group resources: ["secrets"] # Create can not be restricted to a resource name. verbs: ["create"]- apiGroups: [""] # "" indicates the core API group resourceNames: ["tailscale-auth"] resources: ["secrets"] verbs: ["get", "update", "patch"]- apiGroups: [""] # "" indicates the core API group resources: ["events"] verbs: ["get", "create", "patch"]---# Copyright (c) Tailscale Inc & AUTHORS# SPDX-License-Identifier: BSD-3-ClauseapiVersion: rbac.authorization.k8s.io/v1kind: RoleBindingmetadata: name: tailscalesubjects:- kind: ServiceAccount name: "tailscale"roleRef: kind: Role name: tailscale apiGroup: rbac.authorization.k8s.io---# Copyright (c) Tailscale Inc & AUTHORS# SPDX-License-Identifier: BSD-3-ClauseapiVersion: v1kind: ServiceAccountmetadata: name: tailscalePuis on définit donc un Deployment avec le secret qui l’accompagne :
---apiVersion: apps/v1kind: Deploymentmetadata: name: tailscale-subnetspec: replicas: 1 selector: matchLabels: app: tailscale-subnet template: metadata: labels: app: tailscale-subnet spec: serviceAccountName: tailscale containers: - name: tailscale image: ghcr.io/tailscale/tailscale:latest env: - name: TS_KUBE_SECRET value: tailscale-auth - name: TS_AUTHKEY valueFrom: secretKeyRef: name: tailscale-auth key: TS_AUTHKEY - name: TS_ROUTES value: "<POD_IP_RANGE>,<SERVICE_IP_RANGE>" - name: TS_USERSPACE value: "true" securityContext: # Run as a non-root user to mitigate privilege escalation attack attempts runAsUser: 1000 runAsGroup: 1000---apiVersion: v1kind: Secretmetadata: name: tailscale-authstringData: TS_AUTHKEY: tskey-0123456789abcdefLa valeur de TS_ROUTES est à adapter dans votre environnement en fonction des CIDR Réseau choisis pour les PODs et les Services.
La variable TS_AUTHKEY présente dans le secret se trouve sur l’interface Tailscale une fois votre réseau créé, je vous invite à consulter la documentation à ce sujet. Il suffit d’accéder à la page des clés de votre réseau, et de générer une clé d’authentication :
Une fois déployé, le noeud devrait apparaître sur l’interface Tailscale :
![tailscale node])(kubernetes-ingress/tailscale-node.png)
Il faut encore que l’on accepte les routes annoncés par le noeud qui tourne dans le cluster, pour ça on va sur l’UI Tailscale, puis sur le noeud en question on appuie sur ... et on sélectionne Edit route settings, et enfin on valide les routes :

Il ne reste plus qu’à installer Tailscale sur chacun des posts depuis lesquels vous souhaitez accéder à vos services et le tour est joué !
Y’a plus qu’à tester
Et la dernière question, c’est comment on accède à nos services finalement, est-ce que l’on est obligé d’aller récupérer l’adresse IP de chacuns des services auxquels on veut accéder ?
Oui effectivement on peut, mais on a aussi la solution de rajouter un serveur DNS sur le réseau Tailscale, donc autant s’en servir..
On commence par récupérer l’adresse IP du service de notre serveur DNS, dans notre cas c’est coreDNS :
kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGErke2-coredns-rke2-coredns ClusterIP 10.43.0.10 <none> 53/UDP,53/TCP 2dEt on l’ajoute sur la page des DNS sur l’UI Tailscale :

Et enfin, on test que tout fonctionne bien avec un curl :
curl frontend.default.svc.cluster.local
<html ng-app="redis"> <head> <title>Guestbook</title> <link rel="stylesheet" href="//netdna.bootstrapcdn.com/bootstrap/3.1.1/css/bootstrap.min.css"> <script src="https://ajax.googleapis.com/ajax/libs/angularjs/1.2.12/angular.min.js"></script> <script src="controllers.js"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/angular-ui-bootstrap/2.5.6/ui-bootstrap-tpls.js"></script> </head>....Et voilà ! Le tour est joué 😎
Et là c’est le drame : NodePort + LoadBalancer matériel
Je me suis retenu d’en parler jusqu’à la fin, mais je vous vois arriver avec vos gros sabots… Peut-être qu’après la présentation de ces divers façons de faire, vous vous dites…
“Mais pourquoi ne pas simplement utiliser du NodePort sur le port 443, et mettre un LoadBalancer en façade ?”
Si vous vous posez cette question, c’est que vous n’avez probablement besoin que d’une seule adresse IP pour votre Ingress(ou Gateway) Controller.
La question que vous ne vous posez probablement pas c’est : “Qu’est-ce qui se passe le jour où j’ai besoin d’avantages d’adresses ?”
Et là, c’est le drame… On est parti pour bricoler de la translation de port, ou pire encore, déployer des services différents sur chacun des noeuds avec des NodePort sur le port 443 qui gère chacun un applicatif différent… 🤮
C’est déjà terminé 🥲
Et oui, toutes les bonnes choses ont une fin…
Tu vois une typo ? Une config non fonctionnelle ? Ou tu n’aimes pas ma façon d’écrire ? Mon LinkedIn est disponible juste sur la gauche 😉